.png)
Jobs make up the long running tasks in Vidispine. They are created in response to requests that would otherwise not be able to respond in time, such as import, export and transcode requests.
The actions performed by a job is determined by its type. Bound to the type are a number of steps, or tasks, defined by the task definitions. The tasks form a graph, and typically execute in sequence, but it is also possible for tasks to start in parallel. This happens for example when importing and transcoding a growing file. The transfer step will initiate the transfer and then trigger the transcode step to start once enough data (the header) from the file has been transferred.
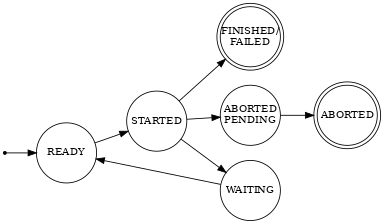
The states of a job are illustrated above. See below for a full description of the states and of the job step states.
Creating jobs
Create jobs by making requests to other RESTful resources:
|
Job type |
Relevant documentation |
|---|---|
|
Import jobs |
|
|
Export jobs |
|
|
Thumbnail jobs |
|
|
Shape update/Essence version jobs |
|
|
File actions |
|
|
Sequence rendering |
|
|
Item list job |
|
|
Shape analyze |
Concurrency
The number of jobs that execute in parallel is determined by the concurrentJobs configuration property.
Job pools
Using job pools, it is possible to decide how many jobs of different priorities that can run concurrently. Job pools are configured using the job pool configuration resource.
If no pools have been defined then <concurrentJobs> controls the number of concurrent jobs. This is the same setting as the concurrentJobs configuration property. So by default the job pool configuration will look like:
<JobPoolListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<concurrentJobs>3</concurrentJobs>
</JobPoolListDocument>
Jobs with priority IMMEDIATE are always started, even if the max concurrent jobs limit is reached. This could impact system performance. To execute the job with IMMEDIATE priority the user must be a super user, that is, have role _super_access_user.
The max concurrent job setting will only have an effect if it is lower then the size of all pools combined.
Priority pools
To start using priority job pools, the job pool definitions must be configured. Priority job pools make it possible to limit the number of concurrent low priority jobs, to make sure that higher priority jobs are able to start even if there are a large number of low priority jobs waiting to be started.
PUT /configuration/job-pool
Content-Type: application/xml
<JobPoolListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<pool>
<priorityThreshold>HIGH</priorityThreshold>
<size>2</size>
</pool>
<pool>
<priorityThreshold>LOWEST</priorityThreshold>
<size>3</size>
</pool>
</JobPoolListDocument>
This configuration will allow at most 3 jobs with a priority of LOWEST to MEDIUM to execute at the same time. It will also allow up to 5 concurrent HIGH/HIGHEST priority jobs, as the second pool will contain jobs with a priority of LOWEST or higher (the priority threshold is the lower bound and pools have no upper priority bound.)
If there is no job pool with a priority threshold that matches low priority jobs then such jobs will not be started. For example, to only let jobs with a priority of MEDIUM or higher to execute:
<JobPoolListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<pool>
<priorityThreshold>MEDIUM</priorityThreshold>
<size>3</size>
</pool>
</JobPoolListDocument>
Dedicated pools
New in version 5.4.
To start using a dedicated job pool, the configuration property dedicatedJobPool must be set to true. See create/modify configuration properties for more information. The job pools must also be configured. If no pools have been defined, the default behaviour will occur where the <concurrentJobs> controls the number of concurrent jobs, regardless if the dedicatedJobPool is set to true or not.
Dedicated job pools make it possible to dedicate certain pools to jobs of certain priority. This can be used to make sure that jobs with all priorities are able to start, regardless of how large the number of other priority jobs that are ready to start.
A job pool, with a priority threshold and a size, defines the upper limit of how many jobs of that priority that are allowed to run in that pool. If there are no ready jobs of that priority, those slots will be used for higher priority jobs.
PUT /configuration/job-pool
Content-Type: application/xml
<JobPoolListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<pool>
<priorityThreshold>HIGH</priorityThreshold>
<size>2</size>
</pool>
<pool>
<priorityThreshold>MEDIUM</priorityThreshold>
<size>3</size>
</pool>
<pool>
<priorityThreshold>LOWEST</priorityThreshold>
<size>5</size>
</pool>
</JobPoolListDocument>
This configuration dedicates certain pools for specific priority jobs. The size of priority threshold HIGH allows 2 jobs of priority HIGH to run in that pool. If there are no jobs with priority HIGH ready to be started, jobs with priority HIGHEST will use those 2 slots.
The size of priority threshold MEDIUM allows for 3 jobs of priority MEDIUM to run in that pool, concurrently with 2 jobs with priority HIGH, as defined by the first pool. If there are no jobs with priority MEDIUM ready to be started, jobs with priority HIGHEST will use those 3 slots. If there are no jobs with priority HIGHEST ready to be started, then the 3 MEDIUM slots will be used by jobs with priority HIGH.
The last defined size of priority threshold LOWEST allows for 5 jobs with priority LOWEST to run concurrently of HIGH and MEDIUM jobs. If there are no jobs with priority LOWEST ready to be started, then jobs with priority HIGHEST or HIGH or MEDIUM or LOW will start, depending if there are jobs of those priorities ready to start, in that specific order.
If there is no defined job pool with a priority threshold that matches lower priority jobs, then such jobs will not be started. For example, to only let jobs with a priority of MEDIUM or higher to execute, remove the job pool with priority threshold LOWEST from the example above. Then jobs of priority LOW and LOWEST will never run.
Jobs of priority IMMEDIATE are always started and therefore do not need to be defined by a pool.
Job problems
Jobs will enter the state WAITING if a recoverable problem has occurred. Depending on the problem the system might resolve itself or require manual assistance, for example if the system is out of storage space.
A system with no job problems will report:
GET /job/problem HTTP/1.1
Content-Type: application/xml
<JobProblemListDocument xmlns="http://xml.vidispine.com/schema/vidispine"/>
A system where the transcoder is unreachable for some reason may report:
GET /job/problem HTTP/1.1
Content-Type: application/xml
<JobProblemListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<problem>
<id>31532534</id>
<type>TranscoderOffline</type>
<job>VX-172716</job>
</problem>
</JobProblemListDocument>
There can be multiple jobs waiting for a problem to be resolved, for example, in case of transcoder or storage problems. For JavaScript problems there will however be one problem per job, as the problem condition is defined by a step specific for each job.
Job tasks
The action performed by a task can be implemented either as a method in a Java class or as a JavaScript. Using JavaScript is recommended for all new applications.
POST /task-definition/ HTTP/1.1
Content-Type: application/xml
<TaskDefinitionListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<task>
<description>A custom JavaScript step</description>
<script><![CDATA[
// This script does nothing but fail the job
job.fatalFail("Testing job failing");
]]></script>
<step>10000</step>
<dependency>
<previous>false</previous>
<allPrevious>true</allPrevious>
</dependency>
<jobType>PLACEHOLDER_IMPORT</jobType>
<critical>false</critical>
</task>
</TaskDefinitionListDocument>
Defining new tasks
See JavaScript tasks on how to create JavaScript tasks.
Task dependencies
The execution order is defined by the step numbers and dependencies of the steps. The dependency element defines which steps a specific step depend on. There is also the parallelDependency element that defines the dependencies that apply if the step is executing as a parallel step.
|
|
The step requires all previous step to finish, before it can start. |
|
|
The step requires the previous step to finish, before it can start |
|
|
The step requires step number N to finish, before it can start |
Visualizing tasks
In order to easily see the dependencies between steps for a particular job type, there is functionality to render the job definition as a graph. In order to render the graph, the Graphviz package is required.
Custom job types
It is possible to define custom job types. Each custom job type is defined with a name and an integer identifier. Both of these must be unique. Task definitions can then be added to the job type, in the same way as described above.
Example
First we create the job type:
POST /task-definition/jobtype/MYCOMPANY_CUSTOM_JOB_TYPE?id=25000 HTTP/1.1
<TaskDefinitionListDocument xmlns="http://xml.vidispine.com/schema/vidispine"/>
Then we can add task definitions to our new job type:
POST /task-definition/ HTTP/1.1
Content-Type: application/xml
<TaskDefinitionListDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<task>
<description>A custom JavaScript step</description>
<script><![CDATA[
logger.log("My custom job is running!");
]]></script>
<step>100</step>
<dependency>
<previous>false</previous>
<allPrevious>true</allPrevious>
</dependency>
<jobType>MY_CUSTOM_JOB_TYPE</jobType>
<critical>false</critical>
</task>
</TaskDefinitionListDocument>
After this has been done, we can now run the job:
POST /job?type=MY_CUSTOM_JOB_TYPE
<JobDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<jobId>VX-29</jobId>
<user>admin</user><started>2016-05-17T12:38:22.999Z</started>
<type>MY_CUSTOM_JOB_TYPE</type>
<status>READY</status>
<priority>MEDIUM</priority>
</JobDocument>